Visual Odometry for Autonomous Navigation
Problem Statement
Precise localization of mobile robots is crucial for autonomous navigation, motion tracking, and obstacle avoidance. Traditional localization methods like GPS, INS, and wheel odometry suffer from significant errors or high costs. Visual odometry (VO) presents a more accurate and cost-effective alternative. Our project aims to compare the effectiveness of traditional geometry-based VO with an end-to-end RNN+CNN model for trajectory estimation.
Motivation
The motivation behind this project is to address the limitations of existing localization methods by exploring VO techniques. By leveraging image data, we aim to improve the accuracy and robustness of localization in environments where traditional methods fall short. The potential benefits include better performance in GPS-denied areas and more reliable navigation for autonomous systems.
Approach
- Geometry-Based Methods:
- Sparse Feature-Based Methods: These methods extract and match feature points from images to estimate motion. While effective, they are prone to drift over time.
- Direct Methods: These methods use photometric consistency to estimate the pose from all image pixels, providing higher accuracy in texture-less environments.


- Learning-Based Methods:
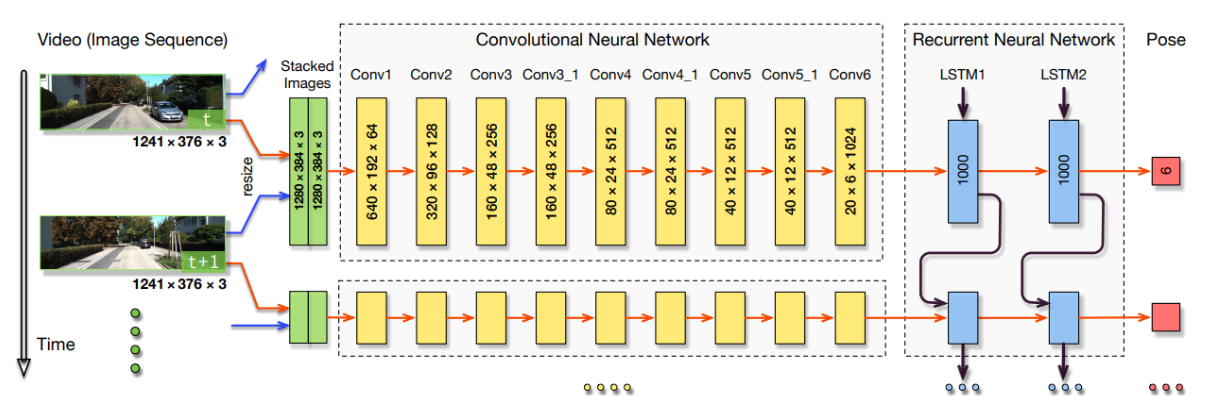
- Deep Learning (DL): We employed CNNs and RNNs to learn features and model sequential information from large datasets. This approach bypasses the need for explicit geometric modeling, allowing the system to infer VO directly from sensor measurements.
Solution
- Geometry-Based VO: We implemented traditional monocular VO using feature detection, tracking, and motion estimation techniques.
- RNN+CNN Model: We developed an end-to-end model utilizing a pre-trained FlowNet CNN and RNNs to predict vehicle trajectory directly from images.
Results
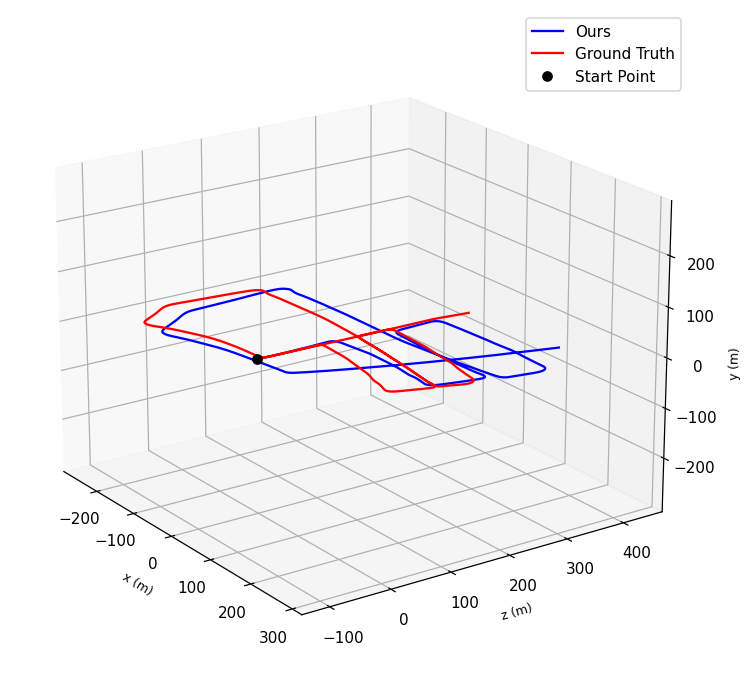
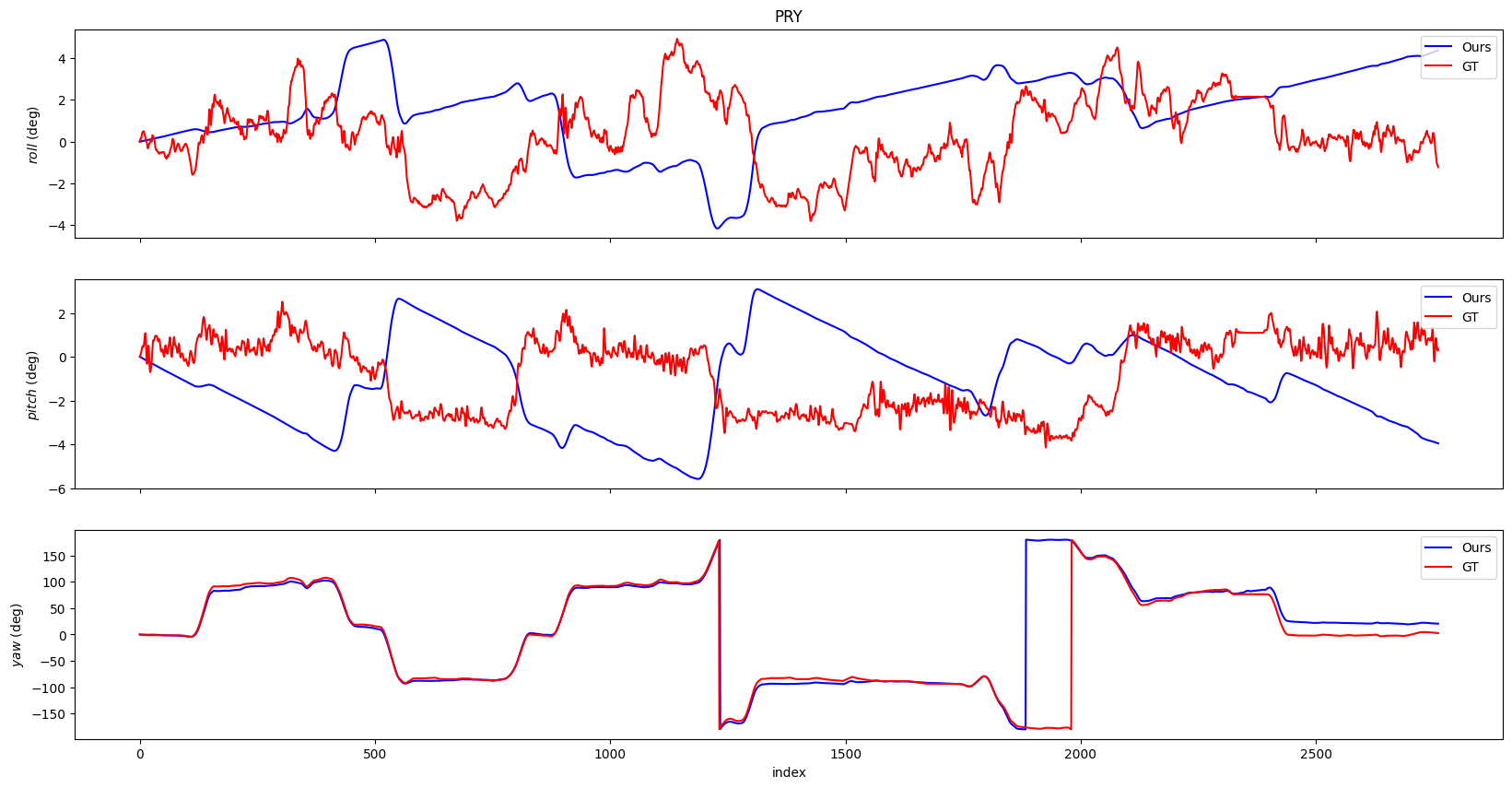
- Experiments: We conducted experiments on the KITTI dataset, training on 7 sequences and testing on 5 sequences.
- Comparison: Both methods performed comparably, with the RNN+CNN model demonstrating its potential by eliminating the need for prior system knowledge and directly inferring poses.
Discussion
The results of our experiments show that the RNN+CNN model is a viable alternative to traditional geometry-based VO methods. The learning-based approach offers simplicity and potential for real-time applications without requiring pre-processed data or extensive geometric modeling. While both methods have their advantages, the RNN+CNN model’s ability to learn directly from data makes it a promising solution for future autonomous navigation systems.