
Pose Estimation through Stable Diffusion
Problem Statement
In the field of computer vision, pose estimation is essential for determining the position and orientation of three-dimensional objects from images. This task becomes particularly challenging when objects are occluded or in cluttered environments, which often results in significant loss of depth information. Traditional feature extraction methods struggle in these complex scenarios, necessitating the development of more robust solutions.
Motivation
The motivation behind this project is to enhance the accuracy and robustness of object pose estimation in environments with occlusions and clutter. By leveraging diffusion features and advanced datasets, we aim to address the limitations of traditional methods and improve the precision of pose estimation even under challenging conditions.
Approach
Our approach involves the following steps:
- Data Utilization: We use the LINEMOD dataset, known for its challenging scenes with occluded and texture-less objects, to train and validate our pose estimation model.
- Model Development: We adapt the Stable Diffusion model to generate training data from diffusion features, simulating scenes often misrepresented in current datasets. This augmentation helps generalize the model.
- Optimizing the Loss Function: We employ the InfoNCE loss function to enhance the model’s feature discrimination capabilities, crucial for distinguishing near-situated features in pose estimation.
- Experimentation and Evaluation: Comprehensive testing across various metrics, including accuracy and error rates, is performed on seen and unseen data to evaluate model performance. Comparisons with common feature extraction methods highlight the improvements made by our diffusion-based approach.
- Results and Analysis: We provide detailed analysis of the model’s performance, identifying circumstances where it excels and where it fails, supported by both qualitative and quantitative results.
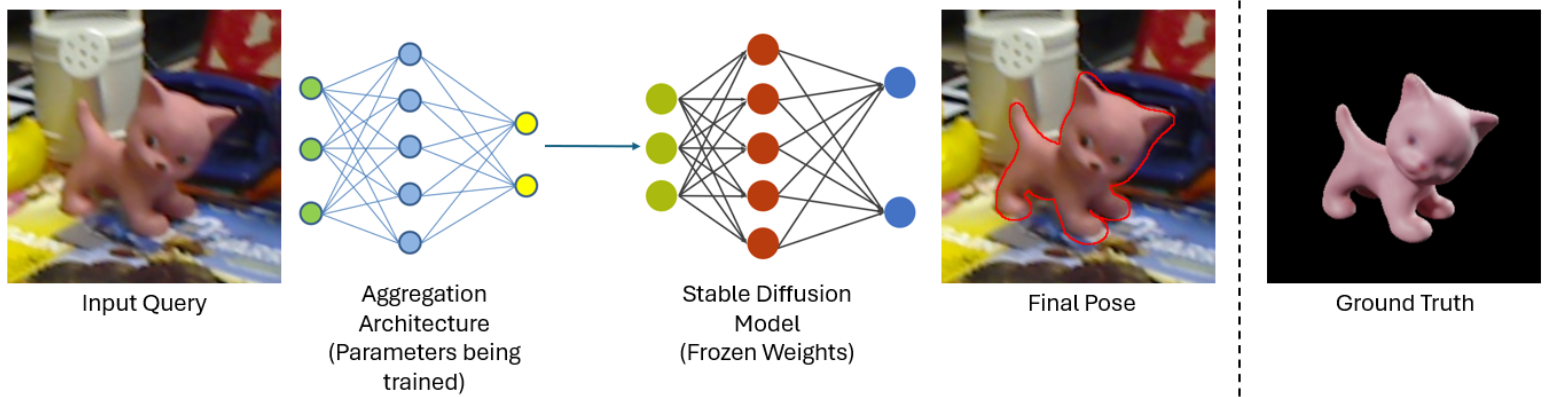
Discussion of Results
Our model demonstrates high accuracy in estimating object poses in clear views and moderately occluded scenes. However, it struggles with high occlusion scenarios, often resulting in incorrect class assignments and erroneous pose estimates. The evaluation metrics show that our method achieves better pose estimation compared to traditional techniques, with notable improvements in accuracy and error rates for seen and unseen objects.
Conclusion
We have presented a method that utilizes diffusion features for template-based object pose estimation, showing significant improvements over traditional methods. Despite some limitations in high occlusion scenarios, our approach demonstrates enhanced accuracy and robustness in pose estimation tasks. Future work will focus on addressing the failures by developing techniques to better handle occlusions and improve overall model performance.

By leveraging diffusion features and advanced datasets, we aim to significantly improve the robustness and accuracy of 3D object pose estimation, even in challenging environments with occlusions and clutter.