Multi Agent Reinforcement Learning for Warehouses
Problem Statement
We study the problem of implementing a centralized Multi-Agent Reinforcement Learning (MARL) environment for Multi-Agent Path Finding (MAPF) problems. MAPF is the problem of looking for collision-free paths for a group of agents from their corresponding start to goal locations. The importance of MAPF comes from its wide application in multi-robot coordination systems in automated warehouses, multi-robot assembly in manufacturing scenarios, and traffic coordination in crossovers. The designed environment can be found at here and the multi-agent -rl policy and training code can be found at here.
Environment Modelling
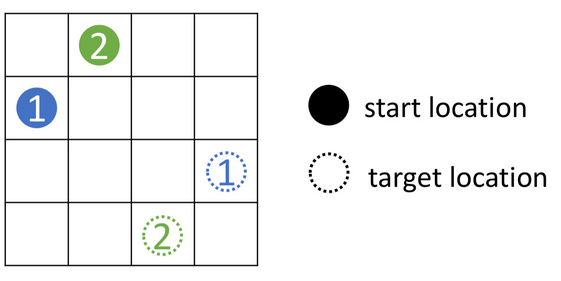
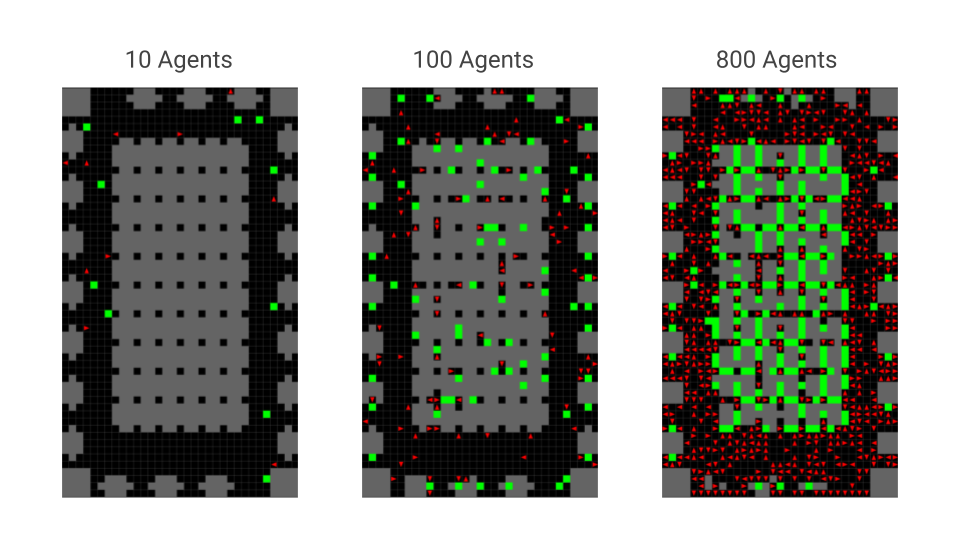
The MARL and MAPF communities are trying to solve the same problem with different approaches. However, the lack of a common environment prevents an apples-to-apples comparison of the results. To resolve this we built a gymnasium-minigrid based simulation environment that can load map layouts from the standard benchmark MAPF configuration or scenario files. A few examples of the environment with various configuration files can be seen in the figures.
Observation Space
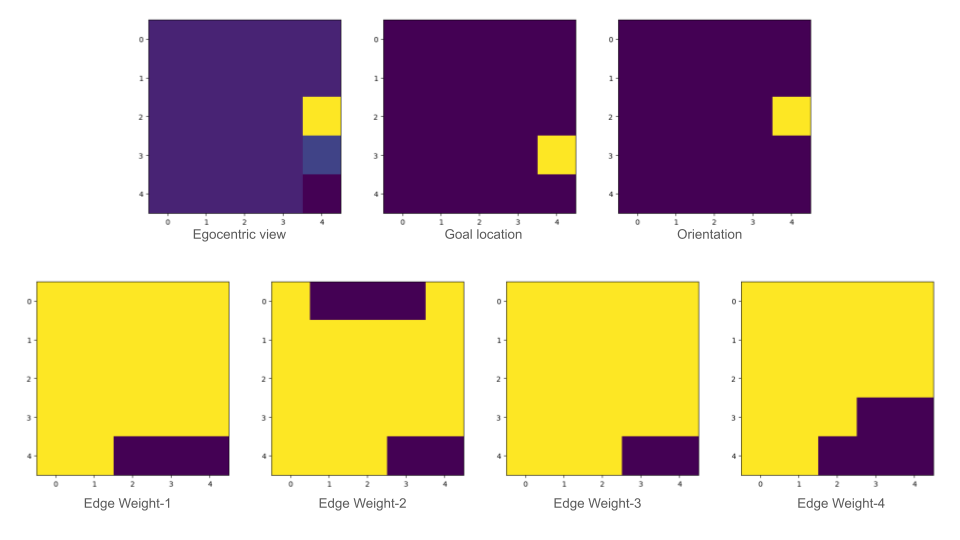
The observation space is a list of 7xHxW for N agents i.e. Nx7xHxW for N agents. The H and W parameters can be passed as environment arguments and represent the height and width of the view that the agent see’s in front of it. Every channel in the HxW image represents the following:
Policy Architecture and Training
In our work, we tackle this problem using a centralized approach. All the work that is out there approaches this problem by training decentralized policy for each agent or decentralized policy with “communication” for MARL.
To do so we first stack the N x C x H x W observation (where C is the number of channels, H & W are the height and width of the observation images respectively) into a N x C x H x W matrix - this is our state s. This is passed through a CNN feature extractor head to get a feature vector of size 128.
The CNN feature extractor has a simple architecture with 2 convolution layers and the output of this is passed to a single-layer MLP which gives this figure.
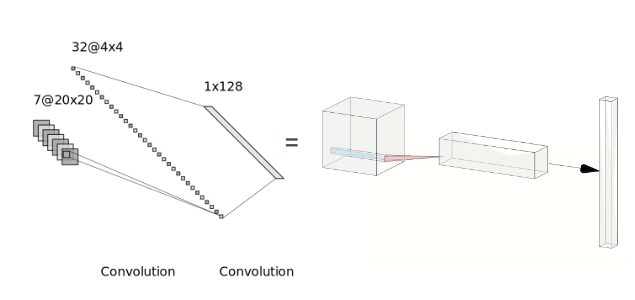
We use stable-baselines-3 to train our policy by leveraging the standardized implementation of PPO. The high-level architecture can be seen in this figure.
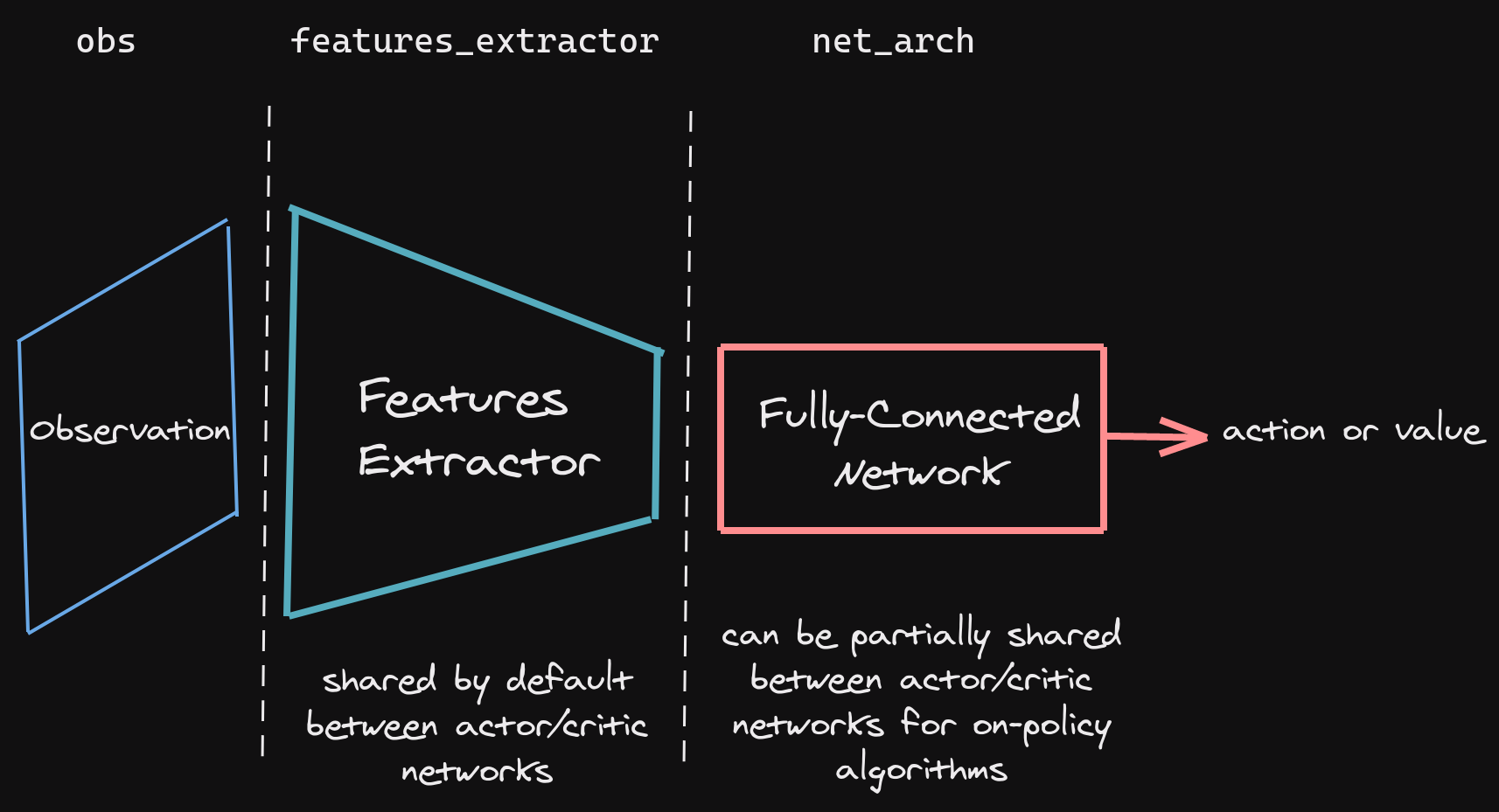
The fully-connected network used for the policy and value function is a 2-layer MLP of size 64. The trained model predicts a N x 4 matrix which is our action matrix $A$ given the stacked observation matrix $s$. This is passed to the environment via the ‘step’ function to get the next observation.
Results
Through our work, we managed to accomplish the following:
- An efficient simulation environment to train RL against where maps can be generated from benchmark MAPF scenario configs.
- A rich image observation space that comprises of:
- Egocentric view of the agent
- Goal position
- Orientation of the agent
- Edge weights
- A continuous action space - capturing the probability of actions to take for each agent.
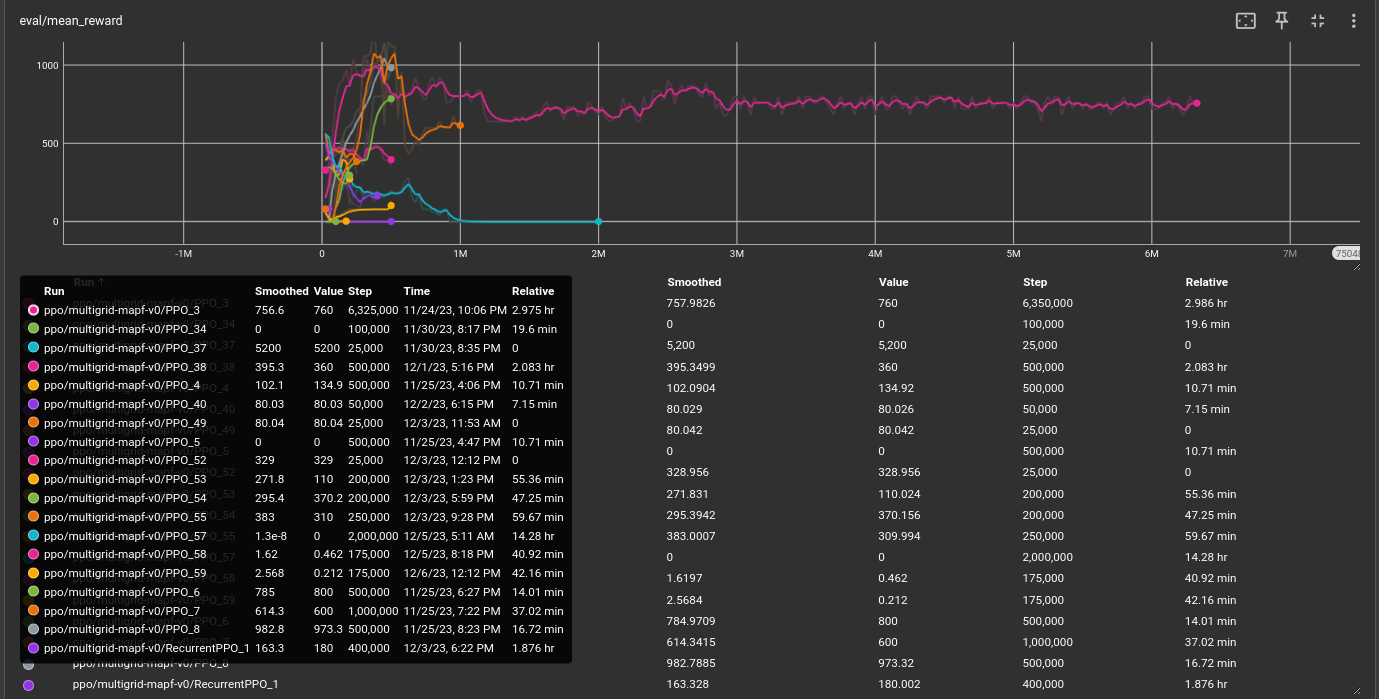
- We were able to set up training of a centralized policy using PPO to predict the actions for each agent given the image observation for each agent. However, the policy performs poorly and is not able to route the agents to their goal location. We discuss ideas to improve the results in the Future Work Section. Figure \ref{experiments} shows the various experiments we tried while training the model and improving the environment and our approach.