
Learning Viewpoint Estimation for Coverage Path Planning
This research presents a novel approach to viewpoint selection for comprehensive surface coverage of 3D parts using reinforcement learning. The authors introduce a Proximal Policy Optimization (PPO) based model that aims to improve both efficiency and generalizability of viewpoint selection strategies. This research is particularly relevant for fields such as robotics, computer vision, and manufacturing where 3D part inspection is crucial.
Traditionally, viewpoint selection for 3D part inspection has relied on deterministic algorithms, which often come with high computational costs and are suitable only for specific 3D parts and inspection scenarios. The proposed PPO-based approach offers several advantages, including the ability to learn from experience, adapt to new situations, and make decisions based on a balance of exploration and exploitation.
Methodology
The methodology involves several key components:
- Dataset: The ABC Dataset, containing one million CAD models, was used for training and evaluation. This comprehensive repository encompasses a diverse range of file formats, including meta, step, para, stl, and obj.
- Action Space: A three-dimensional box using spherical coordinates, allowing for more effective capture of the 3D environment complexity. The use of spherical coordinates enables the model to capture the complexity of the 3D environment more effectively than Cartesian coordinates.
- Observation Space: Defined by a binary vector corresponding to mesh elements in the 3D environment. Each entry in the vector serves as a mask for the indices of the visible elements, with a value of 1 indicating visibility and 0 indicating invisibility.
- Reward Policy: A composite function designed to optimize exploration by minimizing the number of states chosen, rewarding new area discovery, and encouraging state distribution around the object.
- Training Pipeline: Utilizes the Proximal Policy Optimization (PPO) algorithm, known for its training stability and sample efficiency in reinforcement learning.
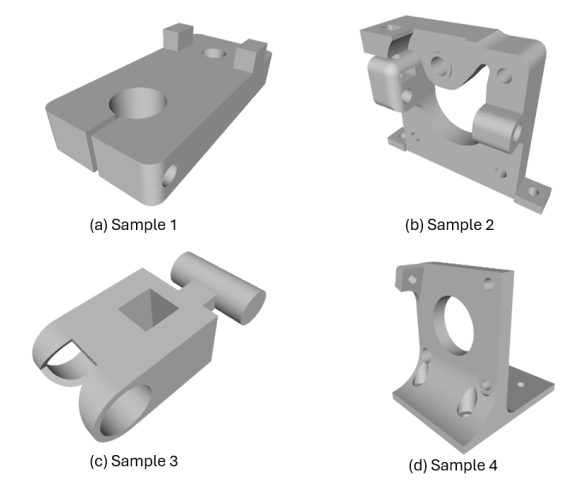
Fig. 1: Samples from the ABC dataset used for training and evaluation. Each mesh was uniformly resampled and normalized to have a fixed number of mesh faces, ensuring consistent observation and action spaces across models.
Observation Model
The Observation Model describes the dynamic relation using which the agent interacted with the environment. It is a function that takes an input agent pose and returns a visibility matrix of the object for that pose. The internal workings of the observation model include defining the observer pose, casting rays to determine visible mesh elements, and creating a binary observation vector.
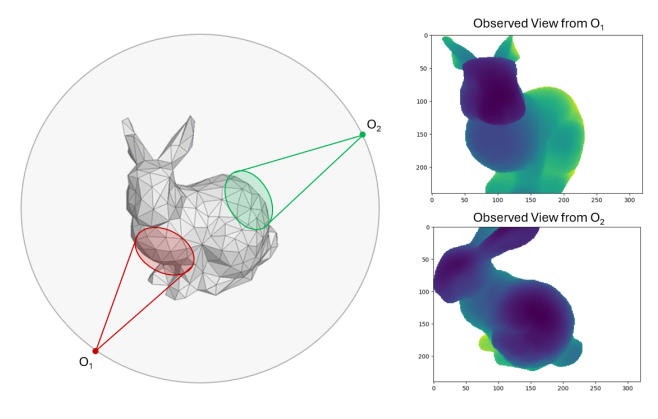
Fig. 2: The agent poses are sampled from a spherical region centered around the object. The sampled poses are fed into the observation model which generates a camera view of the object from that pose.
Proximal Policy Optimization (PPO)
PPO is a policy optimization method used in reinforcement learning to address challenges of training stability and sample efficiency. The key idea is to limit policy updates at each step to ensure the new policy doesn't deviate too far from the old policy. The PPO algorithm introduces a surrogate objective function with a penalty term controlled by a hyperparameter, ε, which determines the maximum allowable change in the policy at each update.
Results
The model demonstrated high accuracy with an average coverage rate of nearly 89%. Key findings include:
- The number of viewpoints generated varied with part topology complexity.
- Generated viewpoints were evenly spread around the model, not concentrated in particular regions.
- Significant reduction in training time was achieved by rewarding environment exploration.
- The model outperformed a greedy implementation of the Next Best View (NBV) algorithm in terms of computation time and, in some cases, coverage percentage.
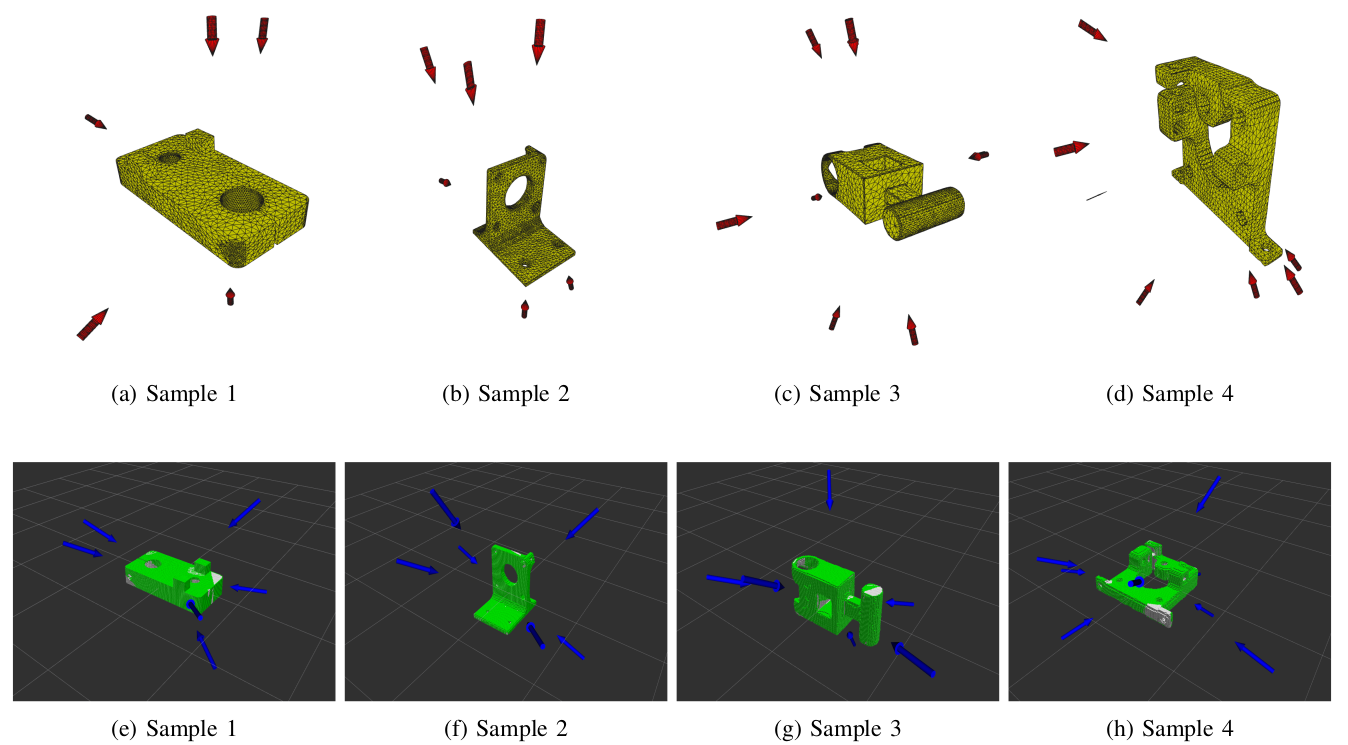
Fig. 3: Performance comparison between the RL agent (top row) and NBV algorithm (bottom row). Red arrows indicate RL agent viewpoints, blue arrows indicate NBV viewpoints. Yellow and green regions show covered surfaces for RL and NBV methods respectively.
Performance Comparison
The trained RL agent was tested against a greedy implementation of the Next Best View (NBV) algorithm. The NBV algorithm serves as a robust benchmark for evaluating the performance of alternative viewpoint selection algorithms. Key differences in performance include:
- The RL agent generally provided better or comparable surface coverage with fewer viewpoints.
- Computation time for the RL agent was significantly shorter than the NBV algorithm, even with thresholds implemented.
- The RL agent demonstrated better adaptability to different object geometries.
Discussion
The proposed reinforcement learning approach shows promise in its ability to adapt to new situations and generalize across different scenarios. Key advantages include:
- Significantly shorter computation time compared to the NBV algorithm, making it more suitable for real-time applications.
- Ability to provide candidate poses more efficiently, potentially reducing the overall inspection time.
- Potential for improved performance with further refinement of the model and training process.
- Greater flexibility in handling diverse object geometries without the need for manual parameter tuning.
However, some limitations were noted:
- The model sometimes fails to cover the complete surface area, particularly in regions with complex topology or occlusions.
- The current approach assumes a static and fully observable environment, which may not always be the case in real-world scenarios.
- The use of a single objective function in the PPO model may not capture all relevant factors in real-world inspection tasks.

Fig. 4: Close-up of Sample 2, showing uncovered regions in complex topologies. Grey areas indicate surfaces not covered by any viewpoint, mainly in areas of highly complex topology such as occluded holes and corners.
Future Work
Several areas for future research and improvement have been identified:
- Development of more efficient reinforcement learning algorithms, potentially incorporating techniques such as transfer learning or meta-learning to reduce training data requirements and improve learning efficiency.
- Integration of synthesis and search-based methods with learning-based approaches, potentially combining deterministic algorithms for initial candidate viewpoint generation with learning-based refinement.
- Addressing the limitations of the current model, such as improving performance in complex topologies and handling dynamic or partially observable environments.
- Exploration of multi-objective optimization approaches to better capture the complexities of real-world inspection tasks.
- Investigation of methods to improve the model's ability to handle occlusions and complex surface geometries.
Conclusion
This research presents a significant advancement in the field of viewpoint selection for 3D part inspection. The proposed PPO-based model demonstrates the potential of reinforcement learning approaches to improve both efficiency and generalizability in this domain. While there are still challenges to be addressed, the results show promise for the application of these techniques in real-world inspection tasks across various industries.
The code and datasets used in this research are available on GitHub, along with installation instructions. The ABC Dataset used for training can be accessed online, and the authors recommend using the RL-Baseline-Zoo for training and evaluating the models.