
Lifelong Multi Agent Planning with Conflict Based Search
Problem Statement
Multi Agent Path Planning
Multi-agent path finding (MAPF) poses a significant challenge as an NP-hard problem with practical applications in surveillance, search and rescue, and warehouses. Specifically, in one-shot MAPF, the objective is to determine collision-free paths for a team of agents from their initial positions to their respective goal positions, minimizing a predefined objective function like makespan (i.e., the time until all robots reach their targets) or the sum of their path lengths.
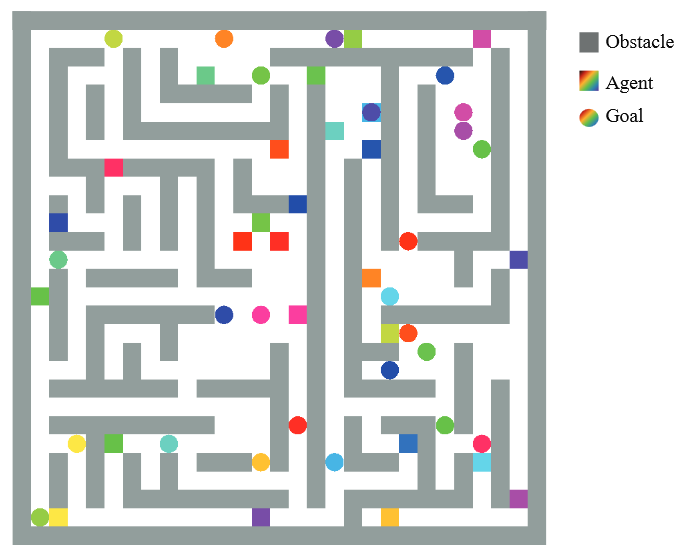
Environment
The League of Robot Runners, sponsored by Amazon Robotics, is a competition where participants tackle one of the most complex optimization challenges: the coordination of multiple moving robots, which is important for industrial applications such as warehouse logistics, transportation and advanced manufacturing.
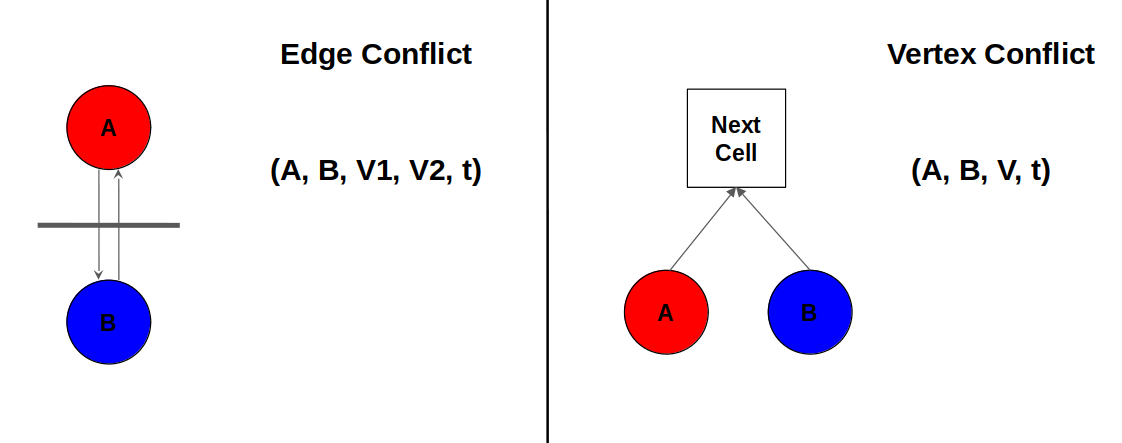
Approach
The algorithm we used to solve the life long multi-agent path finding problem is based on Conflict Based Search. In the images, we outline a strategy for Lifelong Multi-agent Conflict-Based Search (LCBS), designed for resolving the complex Lifelong Multi-Agent Pathfinding (LMAPF) problem, particularly in dynamic environments where agents receive continuous goal updates.
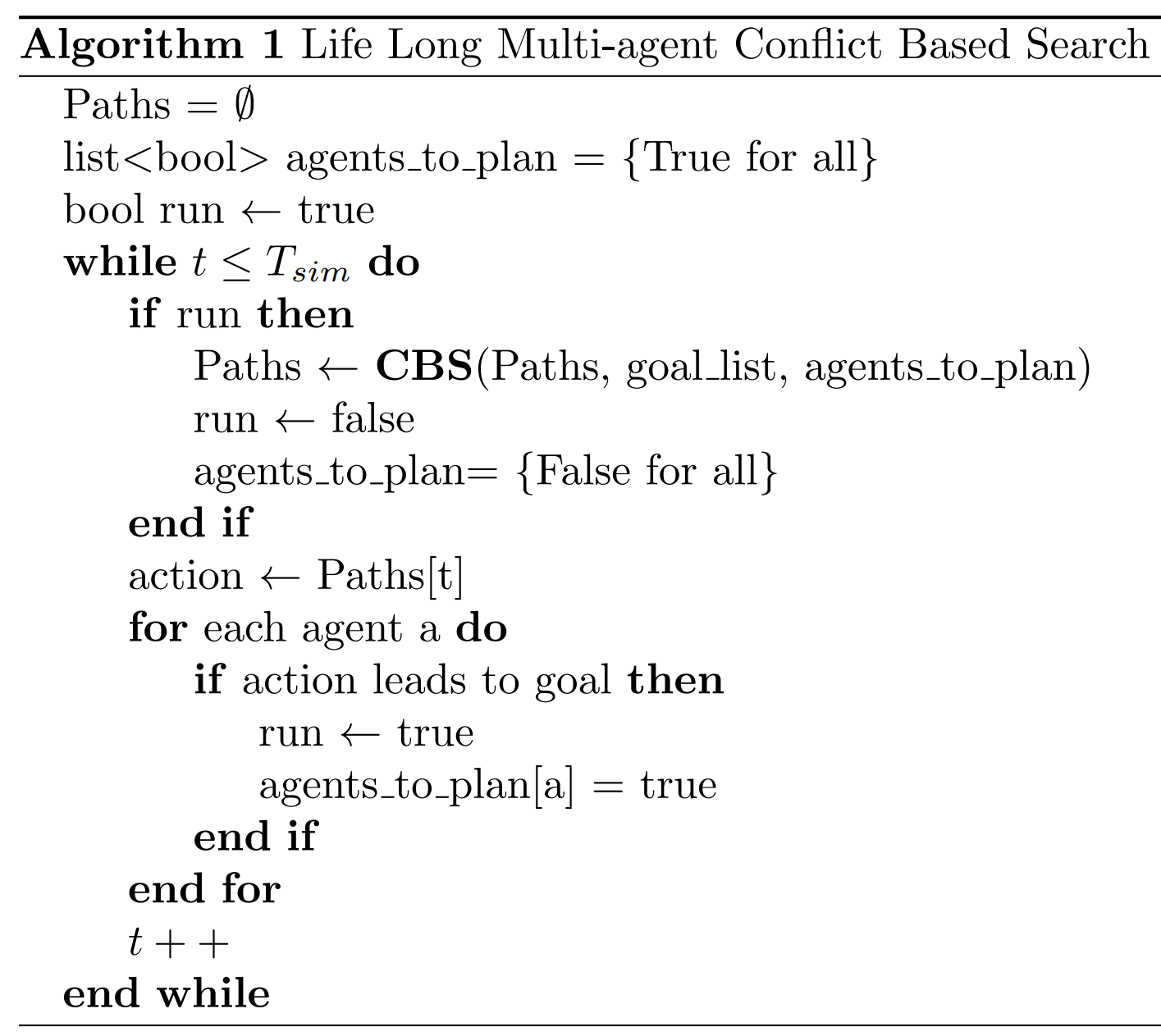
Life Long Multi-agent Conflict-Based Search
This high-level algorithm maintains a list of paths and a boolean flag for each agent, indicating whether a path needs to be planned for them. The system runs in a loop for a specified simulation time, ‘T sim‘. Within each iteration, if the ‘run‘ flag is true, it calls the CBS function to plan paths for the agents. After planning, the ‘run‘ flag is set to false, and all agents’ planning flags are reset to false as well. The agents then execute actions based on the current paths. If an action leads an agent to its goal, the ‘run‘ flag and the agent’s planning flag are set to true, indicating that the paths need to be recalculated in the next iteration due to the changed environment. The time step increments, and the loop continues until the simulation time ends.
This iterative, dynamic approach allows agents to continuously adapt to new goals while managing and resolving conflicts. It is particularly suited to applications requiring high adaptiveness and reactivity, such as robotics in warehouse management, where agents represent robots or autonomous vehicles continuously navigating and fulfilling tasks.

The CBS Function
This function initializes with a given set of paths and a goal list for the agents to plan their routes. The root node solution is updated using low-level planning, which can be A* or Dijkstra. The low-level planner will assign initial paths to the agents based on their goals. The cost of the root solution is calculated by summing the costs of individual paths of all agents. The root node, with no initial constraints, is then pushed onto the OPEN list, which presumably contains nodes that represent possible solutions to be explored.
The algorithm then enters a loop, continuously selecting the best node from the OPEN list based on cost of nodes and checking for conflicts among the paths in the selected node. If no conflicts are detected, the solution is returned. Otherwise, the algorithm identifies the first conflict and for each agent involved, a new node is created with added constraints to avoid the conflict. The solution paths and cost are updated accordingly, and this new node is then pushed to the OPEN list for further considerations.
Results
The larger map with 33x57 cells and more agents (25) resulted in a higher total task completion (3666) but also required more computational time (72.722 seconds). The larger search space likely contributed to increased solve time and the need for a greater number of CBS calls. The smaller map with 32x32 cells and fewer agents (20) showed slightly lower total task completion (3416) but also had a lower solve time (70.821 seconds) and fewer CBS calls (2492).